Liam
24 May, 2015
Paper reading - Weight Uncertainty in Neural Networks
This paper is published by Google DeepMind.
Background
Backpropagation, is a well known learning algorithm in neural network. In the algorithm, the weight calculated is based on the out put of the result. To prevent overfitting and introduce more uncertainty, its often comes with L1 and L2 regularization.
Weights with greater uncertainty introduce more variability into the decisions made by the network, leading naturally to exploration
Reading
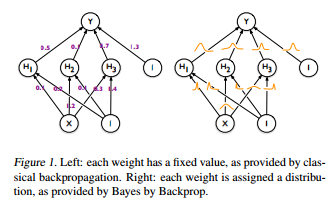
This article introduced a new regularization method called Bayes by Backprop.
Instead of a fixed value, they view neural network as a probabilistic model.

In Dropout or DropConnect, randomly selected activations or weights are set to zero. However in Bayes by Backprop, the activation is set based on its probability. When the dataset is big enough, its similar to the usual backpropagation algorithm, with more regularization.
Result
- When classifying MNIST digits, performance from Bayes by Backprop(1.34%) is comparable to that of Dropout(~=1.3%), although each iteration of Bayes by Backprop is more expensive than Dropout – around two times slower).
- In MNIST digits, Dropconnect(1.2% test error) perform better than Bayes by Backprop.
Personal Thought
This paper comparison based on MNIST test error is not accurate enough, we should compare its false positive result with human eye classification - as some of MNIST labelling is arguable.
Bayes by Backprop might achieve higher performance in specific situation.